Metric Selection for the Objective Evaluation of System Prompts in Large Language Models
Axel Fritz
axel.fritz@alquimia.ai
Alquimia AI
Alex Fiorenza
alex.fiorenza@alquimia.ai
Alquimia AI
March 30, 2026
Abstract
Evaluating the quality of a system prompt for a large language model (LLM) is a non-trivial task. Existing approaches often collapse quality into a single scalar score derived from a single LLM judge call, which lacks scientific grounding and diagnostic value. In this work, we analyze the space of available metrics for prompt evaluation and propose a set of components with distinct root causes, organized by objectivity and availability. Our main proposal for integration in evaluation libraries is grounded in two objective and reproducible metrics as a mandatory core: the Consistency/Stability Rate (CSR), which measures how stable the model's response distribution is under repeated sampling, and the normalized Semantic Entropy (SE), which quantifies uncertainty over the space of meanings of the outputs. Three optional components are added, which the user can enable according to their use case: the Reference Similarity Score (RSS), applicable when reference responses are available, the Instruction Compliance Rate (ICR), applicable when the prompt contains programmatically verifiable constraints, and the Judge Quality (JQ), for those who prioritize exhaustiveness over strict reproducibility. This design decision—privileging objectivity and reproducibility in the core, delegating to the user the incorporation of signals dependent on external models—is formally justified throughout the paper.
Introduction
The quality of a system prompt has a direct impact on the behavior of an LLM in production. Yet, despite the central role of prompt engineering in applied AI, rigorous methods for prompt evaluation remain underexplored. Most practitioners rely on anecdotal comparisons or single-call LLM judges that produce a score with no explicit scientific justification.
This paper addresses the following question: What is a scientifically defensible way to score a system prompt, and what should that score represent?
Our answer is grounded in three observations from the literature. First, a single score is difficult to defend unless the dimensions it aggregates are made explicit [1]. Second, high output consistency under sampling is a meaningful distributional signal of prompt quality, but consistency alone does not imply correctness [2,3]. Third, multi-objective reward models trained on human preference data outperform single-score LLM judges on standard benchmarks, and their advantage lies precisely in operating over a vector of objectives [4].
We propose to return a vector of five normalized signals organized in two tiers. The mandatory core consists of two reference-free distributional metrics: the Consistency/Stability Rate (CSR) [2,3], which measures how often the model produces semantically equivalent responses under repeated sampling, and normalized Semantic Entropy (SE) [9], which quantifies uncertainty over the space of meanings. Three optional signals extend the core when dependencies are available: Reference Similarity Score (RSS), Instruction Compliance Rate (ICR) [5], and Judge Quality (JQ). Scalar aggregation is left as an optional, explicitly calibrated step.
The central empirical finding of this work is that no single signal is sufficient for behavioral prompt evaluation. In a controlled experiment comparing a well-specified, a deliberately wrong, and a minimal system prompt for a customer service bot, we show that:
- [noitemsep]
- CSR and Stability correctly order all three prompts by behavioral consistency but cannot detect what the model is doing wrong.
- RSS cannot distinguish a prompt that follows the wrong protocol (JQ = 0.200) from one that provides no protocol at all (JQ = 0.500)---their embedding distances from the reference are nearly identical (0.599 vs.\ 0.617).
- ICR detects constraint non-compliance with certainty but only for constraints that were explicitly defined.
- JQ is the only signal that exposes active protocol violation: the wrong-instruction prompt scores below the minimal prompt because the model consistently follows bad instructions rather than improvising.
These results justify the compound vector design: each signal exposes a failure mode that the others miss.
Related Work
Self-consistency and distributional signals. [2] propose self-consistency as a decoding strategy: multiple reasoning chains are sampled and the most frequent answer is selected via majority vote. This establishes output frequency as a reference-free signal of model stability. [3] extend this to prompt evaluation, defining self-consistency as the mode frequency among sampled outputs and introducing a mutual-consistency refinement across prompt variants. They report Spearman correlation with ground-truth accuracy and show that GLaPE outperforms raw self-consistency across eight reasoning datasets.
Programmatic instruction verification. [5] propose IFEval, which restricts evaluation to verifiable instructions—those whose compliance can be checked with a deterministic program (e.g., word count, JSON format, keyword inclusion). They define strict and loose compliance metrics at both the prompt and instruction level, providing a reproducible and objective evaluation component.
Prompt perplexity. [6] show that prompts with lower perplexity tend to yield better task performance, interpreting perplexity as a proxy for model familiarity with the prompt. They propose SPELL, a method to select and expand prompt candidates by ranking on perplexity over a held-out sample of inputs.
Multi-dimensional evaluation. [1] argue that human evaluation of natural language generation (NLG) is inherently multi-dimensional (e.g., coherence, fluency, relevance) and that a one-size-fits-all score is scientifically untenable. They reformulate each dimension as a Boolean question answered by a unified model, reporting probabilities of ``Yes'' as dimension-level scores.
Reward models. [7] formalize reward model evaluation using triples (prompt, chosen, rejected) and define accuracy as the rate at which the model assigns a higher score to chosen over rejected. [4] extend this to multi-objective reward modeling: a vector of absolute ratings is predicted and dynamically scalarized via a gating network conditioned on the prompt, arguing that fixed-weight linear combinations are too rigid for general use.
LLM-as-a-judge. [8] propose G-Eval, which uses chain-of-thought followed by structured form-filling to evaluate NLG dimensions, reporting Spearman correlation of 0.514 with human judgments in summarization. They also document systematic biases in LLM judges, including position bias and preference for LLM-generated text.
Method
Notation and Sampling Setup
The central idea of the method is not to evaluate the prompt with a single model response, but to observe how the model behaves when asked the same question multiple times. We call the prompt under evaluation, an input query, and the number of times the model generates a response for each pair .
Formally, are the outputs generated with temperature (which introduces variability between responses) and is the set of queries over which the prompt is evaluated. The result per instance is a vector ; the global prompt result is the average over all queries:
Tier 1 — Core Metrics (Always Applicable)
Tier 1 consists of two components that require no special infrastructure: only model calls. They work with any prompt, any provider, and any dataset.
CSR — Consistency/Stability Rate
A quality prompt should lead the model to give coherent responses to each other, even when run multiple times with positive temperature. CSR measures exactly that: what fraction of the responses falls into the most frequent group.
If we run the same prompt 10 times and 7 responses say essentially the same thing, then CSR = 0.70. A prompt that produces scattered and contradictory responses will have low CSR.
Formally, let be the response extracted from sample (via regex for numeric QA, or semantic grouping for free text). Following [2] and [3]:
[CSR]
For free text, responses are grouped semantically (see ) and CSR is the mass of the largest cluster: , where is the number of responses in cluster . CSR by construction.
SE — Semantic Entropy
CSR only looks at the most frequent group. SE complements that view by measuring the complete distribution of meanings: if responses cluster into a few very dense groups, entropy is low (the model is certain). If they scatter into many different groups, entropy is high (the model is uncertain).
The key difference from token entropy is that SE groups first by meaning, not by form. Two responses that say the same thing with different words count as one [9].
Let be the semantic clusters of the responses, with responses each. In the discrete variant (without needing to access internal model probabilities):
We normalize by so the result falls in , and invert it so that a higher score is better. This normalization requires ; in the degenerate case we define by convention:
Semantic Clustering Strategy
sec:clustering
Both CSR and SE depend on being able to group the responses by semantic equivalence. There are two approaches for determining whether two responses belong to the same cluster:
- [noitemsep]
- Bidirectional NLI: two responses are grouped if a natural language inference model verifies that and . This is the most rigorous method but requires an additional NLI model and has cost in calls.
- Cosine similarity over embeddings: we construct an undirected graph on the responses with an edge between and if , where is the embedding of response and is a configurable threshold, and define clusters as the connected components of this threshold graph (equivalently, single-linkage clustering with similarity threshold ).
We adopt cosine similarity with connected-components over the threshold graph as the clustering strategy for three reasons: it requires no additional model beyond the embedding model already available in the system, the threshold is explicit and configurable by the user, and the cost is significantly lower than NLI.
Effect of threshold . The threshold determines how similar two responses must be to be considered equivalent. Table describes the effect on CSR and SE according to the value of .
[h] Effect of threshold on CSR and SE. tab:tau
| p3.5cm p3.5cm p3.5cm Value of | Behavior | Effect on CSR and SE | When to use |
|---|---|---|---|
| -- | Balanced. Groups paraphrases and style variations; separates responses with different content. | Representative estimates of the prompt's real behavior. | Recommended default configuration. |
| -- | Strict. Only groups nearly identical responses in content and phrasing. | Lower CSR, higher SE. Detects subtle content variations. | High-precision evaluations or prompts with highly structured responses. |
| Very strict. Almost all responses fall into different clusters. | CSR and SE lose diagnostic value — every superficial variation is interpreted as semantic. | Not recommended except for very specific cases. |
The recommended default value is for sentence-transformer embedders in the 22M--110M parameter range (see for empirical justification). Users in domains with high style variability (e.g., conversational responses) can reduce it toward ; values above are not recommended.
Tier 2 — Extended Metrics (Conditional on Dependencies)
These components increase the precision of the vector but require dependencies that are not always available. They are included in only when applicable.
RSS — Reference Similarity Score
CSR and SE measure distributional stability but do not indicate whether the responses are correct. When reference responses are available, RSS provides an objective correctness signal without introducing the variance of an external judge model.
RSS computes the average cosine similarity between each generated response and the reference response , using the same embedding model already used for clustering:
[RSS]
where denotes the embedding of a response. RSS by construction; in practice it falls in for semantically related texts.
Unlike JQ, RSS does not depend on an LLM judge and produces the same result given the same embedder, dataset, and prompt. Its limitation is that embedding similarity captures surface-level semantic proximity but may not detect factual errors that are semantically close to the reference.
ICR — Instruction Compliance Rate
Some prompts include instructions that can be verified with a program, without needing a judge: ``respond in JSON'', ``use fewer than 100 words'', ``include keyword X''. ICR measures what fraction of those constraints are met, deterministically and reproducibly [5].
If the prompt has 3 verifiable constraints and the response meets 2, . If none are met, and it can be used as a hard gate: the output is rejected regardless of other scores.
[ICR]
JQ — Judge Quality (Multi-Rubric)
CSR and SE measure distributional stability, but do not say whether the responses are good. For that we use an LLM judge, but with an important difference from a naïve judge: instead of asking for a single number, we ask it to evaluate the response on four independent dimensions and return a structured JSON.
This forces the judge to reason step by step (chain-of-thought) before assigning each sub-score, reducing the arbitrariness of a single score [8,1].
The final JQ score is the average of the four sub-scores :
[JQ]
[h] Rubric dimensions for JQ.
| Faithfulness to context | No hallucination beyond provided context | |
|---|---|---|
| Instruction adherence | Follows non-verifiable prompt directives | |
| Clarity | Coherent, well-structured response |
Bias mitigation: To reduce position bias documented in LLM judges [8], the evaluation is repeated times with randomized output ordering and results are averaged.
The Metric Vector
The final result of evaluating a prompt over a query is the vector , where each component has a distinct root cause and all are normalized to :
[Metric vector]
where indicates components included only when their dependencies are available.
Experiments
sec:experiments
We evaluate the proposed metric vector on a behavioral benchmark for a customer service assistant. Unlike factual domains---where capable models tend to produce semantically convergent responses regardless of prompt quality---behavioral queries expose prompt quality directly: the correct action (escalation protocol, off-topic redirect, incomplete-input handling) is an arbitrary policy prescribed only by the prompt, and without that policy capable models produce diverse but plausible responses, creating observable variance in all signals.
Experimental Setup
Model and embedder. We use qwen/qwen3-32b via the Groq API with temperature and reasoning\_effort=none to suppress chain-of-thought output that would otherwise contaminate embedding similarity scores (see ). Embeddings are computed with all-MiniLM-L6-v2 (22M parameters). All experiments use samples per query and .
Dataset. The evaluation dataset consists of behavioral queries for a WhatsApp customer service assistant of a Japanese restaurant. Queries cover: three complaints (incorrect order, cold food, delivery delay), two off-topic redirects (competitor recommendation, movie recommendation), one health/safety query (possible food poisoning), two incomplete reservation requests (missing time, missing party size), one discount negotiation, and one aggressive message. All ground-truth reference responses reflect the protocol prescribed by the good prompt.
Prompt variants. Three system prompt variants are evaluated:
- [noitemsep]
- Good: eight explicit behavioral instructions specifying complaint escalation to the encargado (manager), off-topic redirect without answering, incomplete reservation validation (must request all missing data before confirming), health/safety protocol (refer to medical professional and escalate), de-escalation for aggressive messages, and correct discount policy.
- Bad: six explicitly wrong instructions that contradict the correct protocol---resolve complaints directly without escalation, grant any requested discount, confirm reservations without requesting missing data, provide home remedies for food poisoning, and engage freely with off-topic queries.
- Simple: a minimal prompt providing only role identification (124 characters), with no behavioral instructions.
Signals. All five components of are activated: CSR and Stability (mandatory core); RSS with ground-truth reference responses; ICR with a single KeywordConstraint checking for the escalation keyword encargado (mandated by the good prompt in five query types); and JQ with a behavioral rubric objective specifying the correct customer service protocol.
Why Behavioral Queries
Factual queries have a single semantically convergent correct answer derivable from model training. Behavioral queries---complaints, off-topic requests, incomplete inputs---are genuinely ambiguous: a polite, helpful response can take many valid forms. The correct action is an arbitrary policy prescribed only by the prompt. Without that policy, capable models produce diverse but plausible responses, creating observable variance in CSR and Stability. A bad prompt can actively prescribe the wrong policy, producing consistent but incorrect behavior---the failure mode that motivates the multi-signal design.
Results
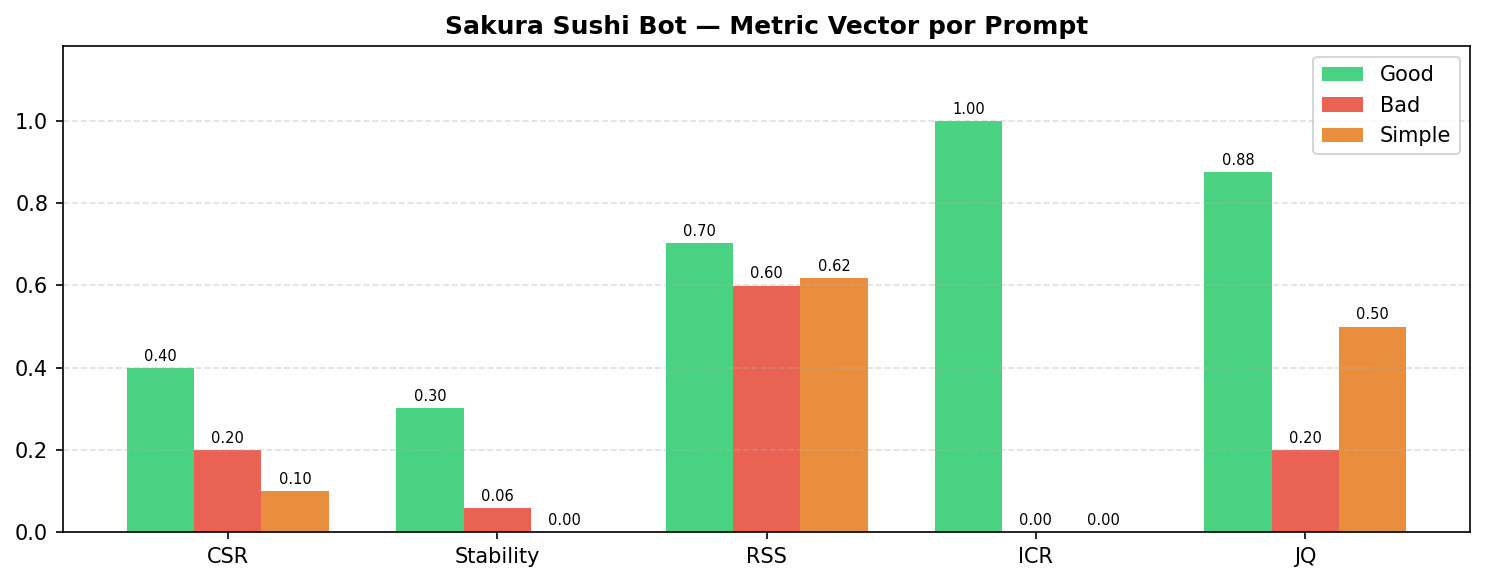
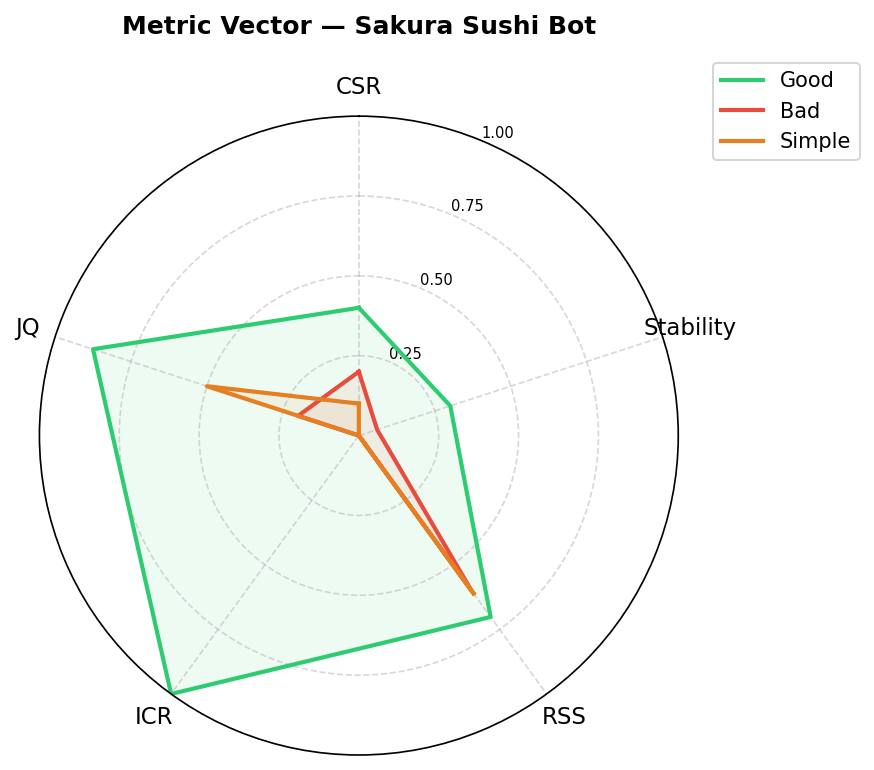
Table reports the mean metric vector per prompt variant averaged over all queries.
[h]
Mean metric vector per prompt variant (, , , qwen/qwen3-32b). Stability .
tab:results
| Bad | 0.200 | 0.060 | 0.599 | 0.000 | 0.200 |
|---|---|---|---|---|---|
| Simple | 0.100 | 0.000 | 0.617 | 0.000 | 0.500 |
Analysis
CSR and Stability: behavioral instructions enforce consistent behavior. All three variants are correctly ordered: Good (CSR = 0.400, Stability = 0.301) Bad (0.200, 0.060) Simple (0.100, 0.000). Absolute CSR values are lower than typical factual evaluations because behavioral queries are genuinely multi-valid in the absence of explicit instructions---even a good prompt cannot fully eliminate semantic variation across samples. The simple prompt achieves minimum Stability (): the model improvises a different behavioral approach on almost every sample, producing maximum semantic entropy.
RSS alone cannot distinguish bad from simple. RSS scores: Good = 0.702, Simple = 0.617, Bad = 0.599. The good prompt is correctly identified as the best by RSS, but bad and simple are nearly indistinguishable---and their ordering is inverted (simple bad). The explanation is that embedding-based similarity captures topic-level semantics: a response that tries to resolve a complaint directly and one that escalates to the manager both discuss the complaint domain and embed similarly relative to the reference. RSS is insufficient as a sole discriminator when prompt failures consist of following the wrong protocol rather than going off-topic.
ICR produces perfect binary separation. ICR drops from 1.000 (Good) to 0.000 for both Bad and Simple---a perfect binary separation. The good prompt always invokes the escalation keyword encargado in the five relevant query types; the bad prompt explicitly instructs against escalation and the simple prompt provides no protocol. This illustrates the value of ICR as a deterministic gate: when a constraint is defined, its violation is detected with certainty and without judge variance.
JQ reveals active protocol violation in the bad prompt. The critical multi-signal finding is the gap between Bad (JQ = 0.200) and Simple (JQ = 0.500). RSS inverts this ordering; JQ corrects it. The bad prompt actively instructs the model to violate the correct protocol---offering direct refunds for complaints, providing home remedies for food poisoning, confirming incomplete reservations without requesting missing data---and the model follows these wrong instructions consistently. The simple prompt, by contrast, produces improvised responses that are sometimes acceptable for straightforward queries, yielding a higher JQ on average. This is the ``consistently wrong'' pattern at the protocol level: consistent behavior (CSR = 0.200) with systematically incorrect responses, a failure invisible to RSS but exposed by JQ.
No single signal is sufficient. Table summarizes the failure modes exposed exclusively by each signal.
[h] Failure modes exposed by each signal in the behavioral evaluation. tab:failures
| Signal | Failure it exposes |
|---|---|
| RSS | Semantic drift from reference behavior (good vs.\ others); insufficient for protocol violation |
| ICR | Constraint non-compliance: escalation keyword never invoked by bad or simple |
| JQ | Active protocol violation in bad prompt; invisible to RSS and ICR alone |
No signal in isolation correctly ranks all three prompt variants or exposes all failure modes. The compound metric vector is necessary for complete diagnostic coverage.
Effect of $\tau$ and $K$
sec:tau_k
We conducted a calibration analysis to characterize the sensitivity of CSR and Stability to the threshold . With and , over 90\% of queries produced , saturating CSR at 1.0 across all prompt variants and eliminating discriminative value. The root cause is that all-MiniLM-L6-v2 places factually similar responses at cosine similarity above 0.80 regardless of surface-level variation. Raising to 0.90 restores non-trivial cluster structure.
A secondary analysis over the grid and (fixed prompt: behavioral good, ) showed that temperature has a limited effect on CSR: the range across -- for a fixed is at most . The main sensitivity lever is . These results justify as the recommended default for sentence-transformer embedders in the 22M--110M parameter range, and confirm that the metric is robust to typical variation in user-configured temperature.
An additional implementation consideration arises with chain-of-thought models: qwen/qwen3-32b emits context field provides domain knowledge accessible to both prompt variants under evaluation, the information asymmetry the experiment is designed to test is eliminated; domain knowledge must be embedded exclusively in the prompt under evaluation, not in a shared context.
Discussion and Limitations
sec:discussion
Why a vector, not a scalar. Three independent lines of evidence support returning as the primary output. UniEval [1] shows that human evaluation of NLG is multi-dimensional and that a unified evaluator must be explicitly designed around those dimensions. GLaPE [3] demonstrates quantitatively that a single signal (SC) can correlate poorly with accuracy. ArmoRM [4] formally argues that fixed-weight linear scalarization of multiple objectives is too rigid, and that context-dependent weighting is required for a scalar to be principled.
Limitations. Tier 2 components introduce dependencies (logprob access, NLI model, reward model) that are not available in all deployment settings. ICR requires that the prompt contain programmatically verifiable constraints, which is not universally the case. Calibration of requires a set of human annotations or reference labels. RSS captures topic-level semantic proximity but cannot detect protocol-level failures: responses that follow the wrong behavioral protocol and responses that improvise freely can embed at similar distances from the reference, making RSS insufficient to distinguish them. For behavioral evaluation, JQ is the primary signal for detecting protocol violation.
Consistent incorrectness. CSR and SE measure distributional stability, not correctness. A prompt that leads the model to consistently produce the same incorrect response will yield high CSR and low SE—values indicating a ``well-defined'' prompt—without implying that the responses are factually correct. This limitation is inherent to any reference-free metric and is documented in [3]. Users who need to validate correctness in addition to stability should enable RSS (if reference responses are available) or JQ.
Future extensions. Two signals are defined in the framework but left for future work. RM (Reward Model Score): when a reward model trained on human preference data is available, the score provides a learned quality signal complementary to the rubric-based judge; multi-objective variants [4] return a vector that can be dynamically scalarized, avoiding fixed-weight rigidity. PP (Prompt Perplexity): prompts with lower perplexity tend to yield better task performance [6]; the normalized component enters with the same sign convention as other signals, but requires access to token log-probabilities, which not all providers expose. Both signals are excluded from the current implementation due to infrastructure requirements that fall outside the scope of a general-purpose evaluation library.
Choice of and its effect on estimates. The number of samples directly affects the reliability of CSR and SE. Table summarizes the expected behavior according to the range of .
[h] Effect of on the quality of CSR and SE estimates. tab:k
| p3.5cm p3.5cm p3.5cm Range of | CSR | SE | Recommendation |
|---|---|---|---|
| -- | Reasonable estimate for prompts with clear behavior. | Acceptable estimate. Moderate Monte Carlo variance. | Default configuration. Adequate for most use cases [3]. |
| -- | Stable estimate. The mode converges with high probability. | Reliable estimate. Low Monte Carlo variance. | Recommended when comparing similar prompts or high precision is needed [2]. |
| Minimal marginal gain. | Minimal marginal gain. | The additional cost rarely justifies the improvement in precision. |
The effect is more pronounced in SE than in CSR: CSR only needs to stabilize the majority group, while SE requires estimating the mass of all clusters, including minority ones. Therefore, for prompts with ambiguous behavior—where high entropy is expected—it is recommended to use so that small clusters are correctly represented.
Conclusion
The core contribution of this work is a principled decomposition of prompt quality into orthogonal, independently measurable signals. The decomposition matters because prompt failures are heterogeneous: inconsistency, protocol violation, constraint non-compliance, and semantic drift are distinct phenomena that require distinct detectors. Collapsing them into a single score does not aggregate information---it destroys it.
The practical implication for practitioners is that the choice of which signals to activate is itself a diagnostic decision. A prompt that scores well on CSR but poorly on JQ is a different kind of failure than one that scores poorly on both---the former is consistently wrong, the latter is incoherent. The vector makes this distinction visible; a scalar cannot.
The fundamental limitation of the mandatory core remains that it measures consistency, not correctness. This is not a deficiency to be fixed but a deliberate scope boundary: reproducibility requires reference-free metrics, and reference-free metrics cannot verify ground truth. Users who need correctness guarantees must supply reference responses (RSS), define verifiable constraints (ICR), or accept the reproducibility trade-off of a judge (JQ). The framework is designed to make that trade-off explicit rather than hide it inside an opaque score.
plainnat refs
References
- [1]Zhong et al. (2022). Towards a Unified Multi-Dimensional Evaluator for Text Generation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing.
- [2]Wang et al. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models. International Conference on Learning Representations.
- [3]Sclar et al. (2024). GLaPE: Gold Label-agnostic Prompt Evaluation and Optimization with Consistency Measures. arXiv preprint arXiv:2402.02408.
- [4]Wang et al. (2024). Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts. arXiv preprint arXiv:2406.12845.
- [5]Zhou et al. (2023). Instruction-Following Evaluation for Large Language Models. arXiv preprint arXiv:2311.07911.
- [6]Xu et al. (2022). SPELL: Semantic Prompt Evolution based on a LLM. Findings of the Association for Computational Linguistics.
- [7]Lambert et al. (2024). RewardBench: Evaluating Reward Models for Language Modeling. arXiv preprint arXiv:2403.13787.
- [8]Liu et al. (2023). G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing.
- [9]Kuhn et al. (2023). Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. International Conference on Learning Representations.