Agentic Evaluation Metric: pass@K, pass^K, and Tool Correctness for Multi-Turn AI Agent Assessment
Axel Fritz
axel.fritz@alquimia.ai
Alquimia AI
Alex Fiorenza
alex.fiorenza@alquimia.ai
Alquimia AI
April 6, 2026
Abstract
Most agent evaluation frameworks score each conversation turn independently and report a single accuracy number. This hides two critical production concerns: how often a fully correct end-to-end conversation can be expected across repeated attempts, and where exactly tool usage breaks down when it does. We present the Agentic metric, a conversation-level evaluation framework available in the Fair Forge library, that directly addresses both. A conversation is treated as an atomic unit: it passes only if every turn is correct. From the global success rate we derive pass@K~---the probability of at least one correct result in attempts---and pass\^{K}~---the probability of consecutive correct results. Together they expose the gap between best-case and consistent reliability. A Tool Correctness score decomposes tool usage into four independently scored dimensions (selection, parameters, sequence, utilization), pinpointing exactly where the agent deviates from the expected behaviour. In our experiments, an agent scoring achieves pass@5 yet pass\^{}5 ---a gap that a single accuracy number would completely obscure. A built-in classification table maps any (pass@1, pass\^{}3) pair to a deployment readiness tier. Both frequentist and Bayesian estimation are supported, the latter producing credible intervals that are essential when fewer than 20 conversations are available.
Introduction
Modern AI assistants operate as agents: they receive a user query, reason over it, call external tools (APIs, calculators, search engines), and produce a final answer that integrates those tool results. Evaluating such systems requires going beyond surface-level text similarity. Two fundamental questions arise that existing metrics do not jointly address:
- [leftmargin=*]
- Reliability: How often does the agent produce a fully correct conversation when given independent attempts?
- Tool fidelity: When the agent calls tools, does it select the right ones, pass the correct parameters, respect the expected execution order, and actually use the results in its final answer?
LLM-based evaluation judges [2] have shown strong correlation with human judgment for open-ended text, but they are ill-suited to assess structured tool invocations. Conversely, exact-match approaches for tool calls [4] do not capture partial credit or graceful degradation. The Agentic metric combines an LLM judge for answer correctness with a deterministic rubric for tool correctness, providing a complete picture of agent behaviour.
Background
pass@k in Code Generation
[1] introduced pass@k to evaluate code-generation models: given sampled programs, at least one must pass all unit tests for the problem to be considered solved. The estimator is:
where is the total number of samples and is the number of correct samples. For large this converges to the Bernoulli estimate with .
Agent Tool Use
The ReAct framework [3] formalised the interleaving of reasoning and tool-calling actions in LLM agents. Subsequent work such as the Berkeley Function Calling Leaderboard [4] established benchmarks for evaluating function-calling accuracy, but these benchmarks focus on single-turn, single-tool scenarios and do not address multi-turn conversation reliability.
The Agentic Metric Framework
Conversation-Level Evaluation
The central design choice of the Agentic metric is to treat a conversation as an atomic unit. A conversation consists of interaction turns , each pairing a user query with an agent response. A conversation is fully correct if and only if every turn is individually correct:
where is the ground-truth answer for turn , is a configurable threshold (default 0.7), and is the LLM judge described in Section. This all-or-nothing criterion mirrors real deployment requirements: an agent that fails mid-conversation leaves the user without a usable result.
pass@K
sec:passk
Let be the number of distinct conversations evaluated for a given task, the number that are fully correct, and the estimated success rate. The probability that at least one of independent attempts succeeds is:
This metric answers the question: ``If I run the agent times on this task, what is the probability I obtain at least one correct result?'' It is particularly relevant in agentic pipelines that can afford to retry or run multiple samples in parallel [1].
pass\^{
K sec:passpowk
While pass@K measures best-of- reliability, it does not capture consistency. An agent with achieves pass@5 but will fail on average half the time in production. We therefore introduce pass\^K, the probability that consecutive attempts are all correct:
This metric answers: ``What is the probability that the agent is correct every single time over consecutive requests?'' Together, pass@K and pass\^K characterise both the ceiling (best-case) and the floor (worst-case consistency) of agent reliability.
Agent classification. Table shows how the joint interpretation of pass@1 and pass\^3 yields actionable deployment guidance.
[h] Agent reliability classification by pass@1 and pass\^3. tab:classification
| -- | Functional but inconsistent | |
|---|---|---|
| -- | --- | Needs improvement |
| --- | Not ready |
Tool Correctness
sec:tool
Tool calls are evaluated separately from answer text. For each interaction
turn that includes tool usage, a ToolCorrectnessScore is
computed across four dimensions:
[leftmargin=2em] [Selection ()] Whether the agent invoked the expected set of tools. Scored as the Jaccard-style ratio of matched versus total unique tool names, penalising both missing and spurious calls.
[Parameters ()] Whether the arguments passed to each tool match the expected values. Scored as the fraction of parameter keys whose values match exactly across all expected tools.
[Sequence ()] Whether tools were invoked in the expected order, when is set. Scored as the fraction of tools whose step index matches the ground truth; set to 1.0 when ordering is declared irrelevant.
[Utilization ()] Whether the tool results were incorporated into
the final answer, captured by the boolean field
final\_answer\_uses\_tools.
The overall tool correctness score is a weighted sum:
with default weights (equal importance). Weights are fully configurable to reflect domain requirements; for instance, a financial calculation agent may assign higher weight to parameter accuracy than to sequence.
A turn is classified as tool-correct if (default 1.0, requiring perfect tool execution).
LLM Judge for Answer Correctness
sec:judge
Answer correctness at each turn is scored by an LLM judge following the G-Eval paradigm [2]. The judge receives the agent's answer and the ground-truth answer and returns a continuous score in according to a strict rubric that penalises factual errors, spelling mistakes, and incomplete responses. The rubric design follows two principles:
- [leftmargin=*]
- Strictness: Typos and spelling errors are penalised even when the core fact is correct, reflecting the quality bar of production deployments.
- Factual primacy: Factually incorrect answers receive scores below 0.3 regardless of formatting or verbosity.
The judge supports any LangChain-compatible BaseChatModel, making the
metric provider-agnostic. A retry mechanism handles cases where the model does
not adhere to the requested output format, ensuring robustness across model
families.
Statistical Modes
The Agentic metric supports two statistical modes for estimating :
Frequentist mode returns the point estimate and derives pass@K and pass\^K directly from it. This mode is recommended when is large enough that sampling uncertainty is negligible.
Bayesian mode places a Beta prior on , samples from the posterior , and propagates uncertainty through the pass@K and pass\^K formulas to produce credible intervals. This mode is recommended when is small (e.g., fewer than 20 conversations), producing intervals of the form at a configurable confidence level.
Experiments
sec:results
Experimental Setup
We evaluate a math-assistant agent on a dataset of multi-turn
conversations. Each conversation consists of arithmetic reasoning
turns in which the agent is expected to invoke a calculator tool
and incorporate the result into its final answer. The ground-truth answers
and expected tool calls are known for every turn, enabling both LLM-judge
scoring and deterministic tool evaluation. The judge is llama-3.3-70b-versatile
served via the Groq API, with an answer-correctness threshold of
and a tool-correctness threshold of .
Per-Conversation Results
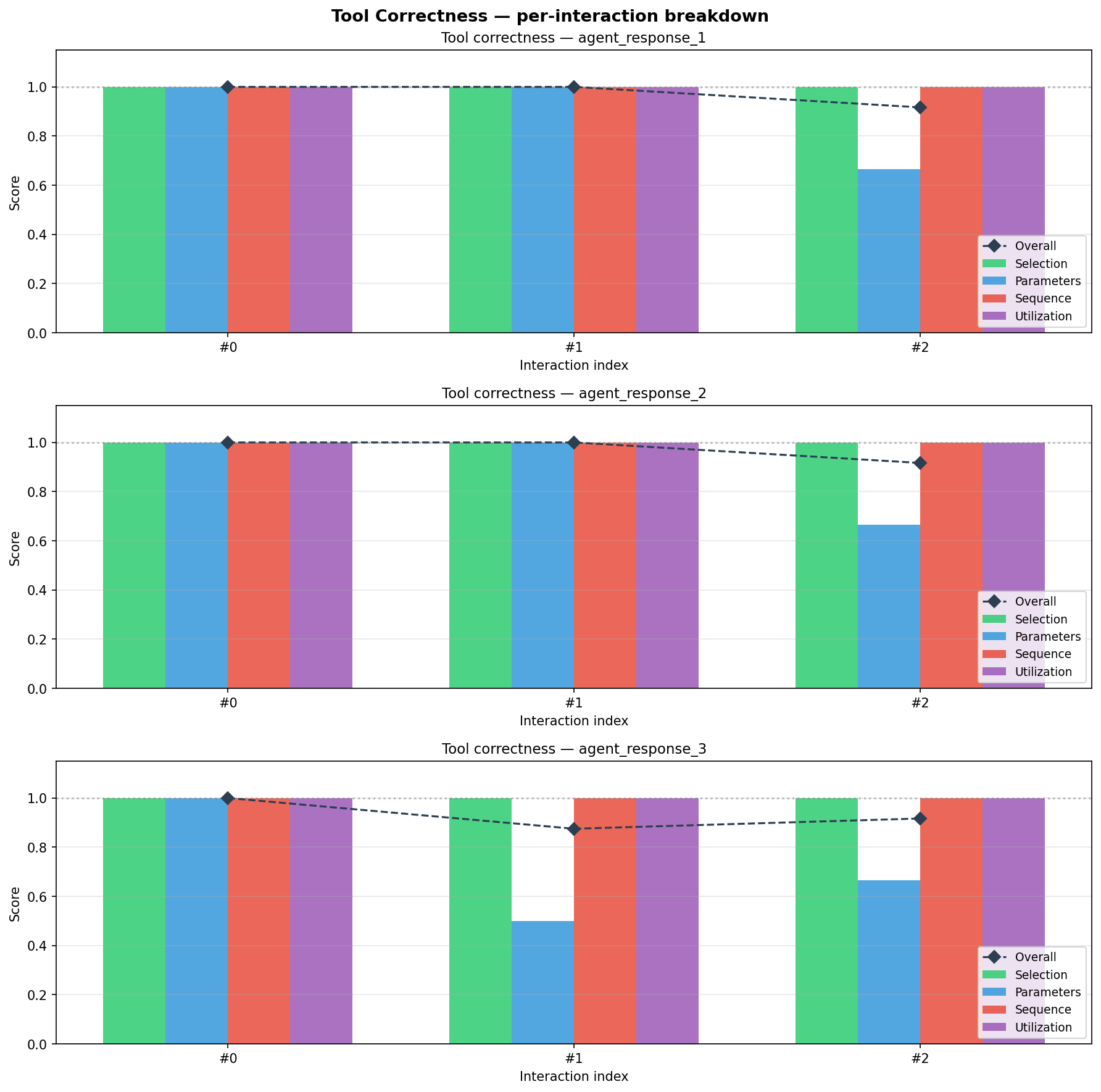
Table summarises the per-conversation outcome. Conversation 3 fails because the agent produces an incorrect first answer (score 0.0) despite correctly answering the remaining two turns; under the atomic conversation criterion this single error disqualifies the entire conversation.
[htbp] Per-conversation evaluation results (, turns). tab:results
| 2 | agent\_response\_2 | [0.95, 0.95, 0.95] | 3/3 | PASS |
|---|---|---|---|---|
| 3 | agent\_response\_3 | [0.00, 0.95, 0.95] | 2/3 | FAIL |
The global success rate is . Applying the classification from Table, this agent falls in the Not ready tier (pass@1 ), indicating that it requires targeted improvement before production deployment.
pass@K and pass\^{
K
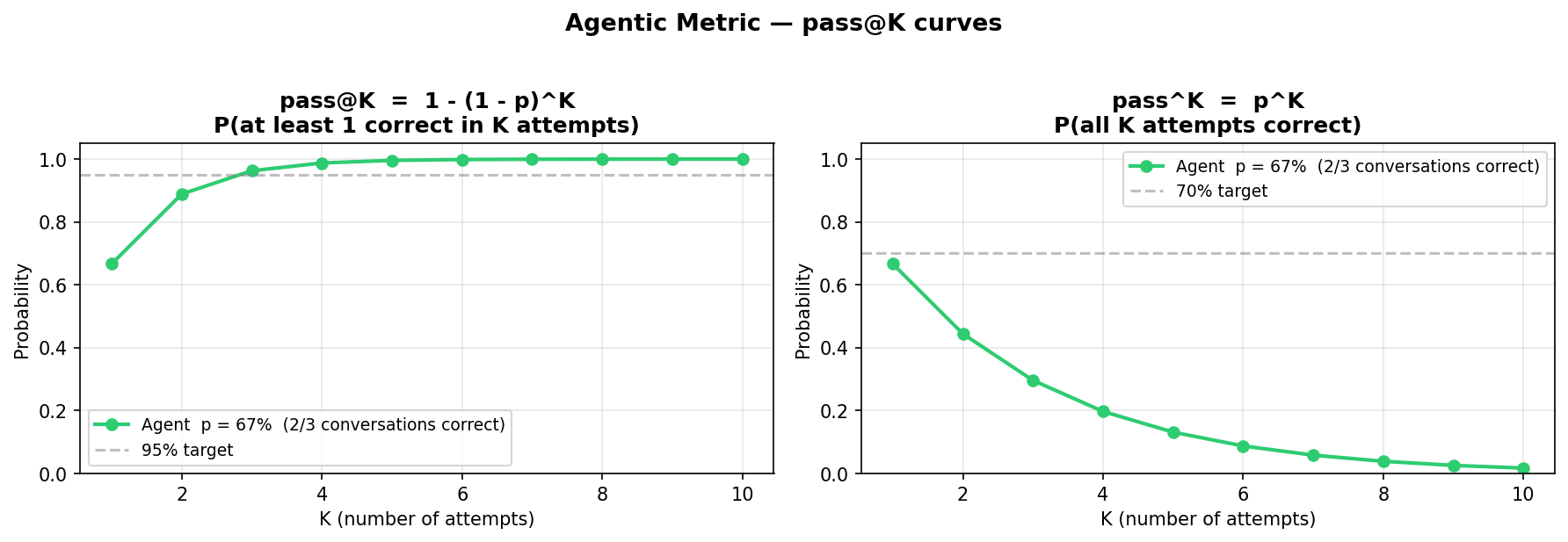
Table shows how both metrics evolve with . The divergence between pass@K and pass\^K illustrates the reliability gap: while the agent can be expected to succeed at least once in five attempts with very high probability (pass@5 ), the probability of five consecutive correct conversations is only , reflecting the underlying success rate.
[htbp] pass@K and pass\^K for , . tab:passk
| 2 | 0.889 | 0.444 |
|---|---|---|
| 3 | 0.963 | 0.296 |
| 4 | 0.988 | 0.198 |
| 5 | 0.996 | 0.132 |
Figure plots the full pass@K and pass\^K curves, showing the asymptotic growth of pass@K and the exponential decay of pass\^K. The widening gap between the two curves is a direct visual indicator of reliability inconsistency.
Tool Correctness
Figure presents the tool correctness breakdown across all evaluated conversations. Conversations with annotated tool calls are scored across the four dimensions; in our dataset, the agent invokes the correct tool, passes the expected parameters exactly, respects the declared step order, and incorporates the result into its final answer.
Value and Differentiation
Existing agent benchmarks such as AgentBench [5] evaluate agents on task completion but do not decompose reliability into best-of- vs.\ consistency dimensions, nor do they provide a modular tool correctness rubric that can be weighted per domain. The Agentic metric contributes three distinct values:
- [leftmargin=*]
- Reliability spectrum: The pair (pass@K, pass\^K) captures both the potential ceiling and the consistency floor of an agent, enabling richer comparisons than a single accuracy number.
- Actionable tool diagnostics: The four-dimensional tool score pinpoints where tool usage fails—wrong tool selected, wrong parameter, wrong order, or result not used—guiding targeted fine-tuning.
- Deployment-oriented framing: By treating a conversation as atomic and by letting the user choose to match their deployment scenario, the metric directly answers the question a practitioner asks before shipping an agent to production.
Conclusion
We presented the Agentic metric, a conversation-level evaluation framework for AI agents. By adapting the pass@K estimator from code generation to multi-turn dialogue, introducing the complementary pass\^K consistency measure, and pairing them with a structured four-dimensional tool correctness rubric, the metric provides practitioners with both a reliability profile and an interpretable diagnostic tool.
The experiments demonstrate that the framework surfaces diagnostically meaningful distinctions that coarser metrics miss. In our three-conversation evaluation, a single factually wrong turn in Conversation 3 brings the global success rate to , which the classification table immediately labels as Not ready. The pass@K/pass\^K pair then quantifies precisely how many attempts a downstream system would need to tolerate before expecting a correct result. This combination of conversation-level strictness, probabilistic reliability estimation, and deterministic tool diagnostics is, to our knowledge, not offered by any existing open-source evaluation library.
The metric is available as part of the Fair Forge library and supports any LangChain-compatible LLM judge. The implementation is open-source at https://github.com/Alquimia-ai/fair-forge.
plainnat agentic_en
References
- [1]Chen et al. (2021). Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374.
- [2]Liu et al. (2023). G-Eval. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing.
- [3]Yao et al. (2022). ReAct. arXiv preprint arXiv:2210.03629.
- [4]Yan et al. (2024). Berkeley Function Calling Leaderboard. arXiv preprint arXiv:2402.04247.
- [5]Liu et al. (2023). AgentBench. arXiv preprint arXiv:2308.03688.